
Why Enterprises Are Exiting HDFS

Hardware Refresh Cycles
Dreading the next $5M hardware procurement cycle? Move to Opex.

Brittle Upgrades
Spending months planning a simple version upgrade? Databricks is serverless and always current

Rigid Scaling
Buying servers just for peak holiday traffic? Scale compute up/down instantly on the cloud.
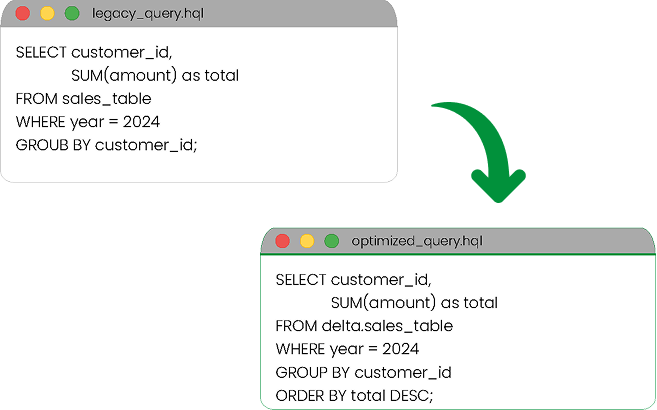
The Secret Sauce: Automate Hive-to-Spark Conversion
Don't Rewrite SQL Manually,
Use Our Converter
We parse your existing HiveQL and Impala scripts and auto-generate optimized PySpark code.
Automatic syntax translation with 95% accuracy
Performance optimization recommendations
Maintains business logic integrity
The 4-Step De-Risk Migration

Metadata
Analysis
We scan the Hive Metastore to map table dependencies and "Hot" vs "Cold" data.

Data
Movement
Distcp / WanDisco setup to move HDFS blocks to Object Storage (S3/Azure Blob).

Code
Transpilation
Automated conversion of Oozie workflows to Databricks Workflows.

Performance
Tuning
Optimizing file sizes (Z-Ordering) and converting Parquet/ORC to Delta Lake format.
Technical FAQ
We refactor Java UDFs to native Spark functions for better performance. Our team analyzes each UDF to ensure equivalent or improved functionality in the Databricks environment.
We use PrivateLink and encrypted channels for all data movement. Your data never touches the public internet, and we implement end-to-end encryption with your own keys.
Yes, Databricks SQL offers a familiar ANSI-compliant interface. Your analysts can continue using standard SQL without retraining. We also support JDBC/ODBC connections for BI tools.
The Hardware Refresh Deadline is Coming
Don't lock yourself into another 3-year depreciation cycle.
