Vectorized execution
Processes data in batches for higher CPU efficiency and fewer interpreter overheads.


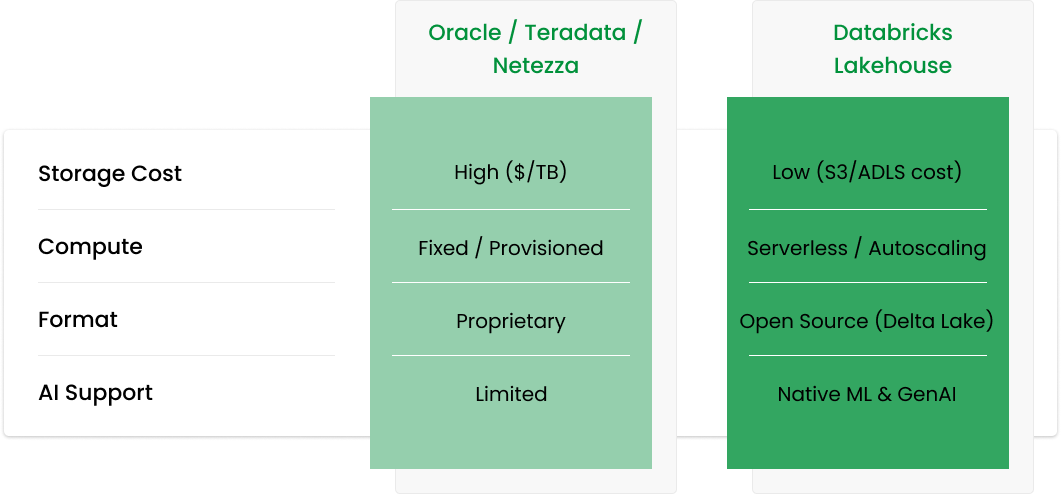
Paying millions annually just to keep the lights on? Databricks utilizes a consumption-based pricing model.

Queries queueing up on Monday mornings? The Lakehouse scales compute independently of storage.

Cannot query unstructured data (JSON, Images) alongside your tables? Databricks handles both.
Databricks isn’t just “Spark” anymore. It uses the Photon Engine—a C++ vectorized execution layer designed to accelerate SQL workloads at scale.

Processes data in batches for higher CPU efficiency and fewer interpreter overheads.

Optimized for ANSI-SQL analytics, joins, aggregations, and complex query plans.

Scale clusters up or down without paying to keep storage hot.
Scale clusters up or down without paying to keep storage hot.

Interpretation: lower execution time equals higher throughput and fewer compute-hours—directly reducing cost at equal or better SLAs.
You don’t need to retrain your entire team in Python. Databricks SQL provides a familiar ANSI-SQL environment with dashboards and visualizations
ANSI-SQL editor and warehouses
Dashboards and scheduled queries
Fine-grained governance with Unity Catalog


Mapping Oracle data types to Delta Lake types.

Refactoring stored procedures into modular, testable PySpark or Databricks SQL.

High-throughput parallel ingestion via JDBC/Parquet.

Re-applying your grants, roles, and row-level security.
Let us build a Proof of Value (POV) in 2 weeks to prove the savings before you sign that check.
