Automated Gates
Every run enforces expectations. If records violate rules, they’re dropped or isolated.


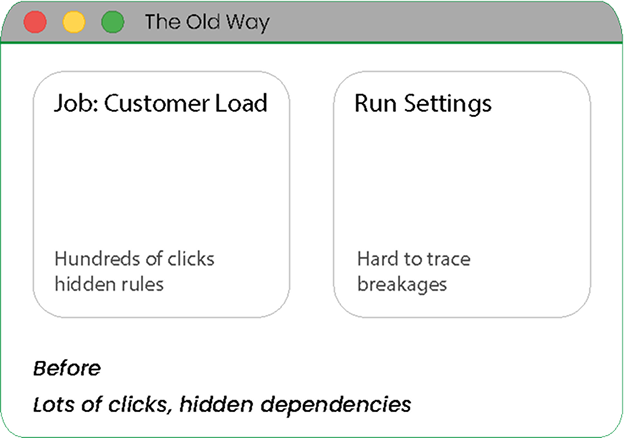
Trying to find an error in a 500-step Informatica mapping? Good luck.

Storing XML exports in Git isn't real version control. You need granular diffs.

Pipelines break silently, and you only find out when the CEO asks where the dashboard is.
Separate the platform from the logic. Let Databricks run reliable pipelines, while dbt makes transformation logic readable, testable, and reviewable.
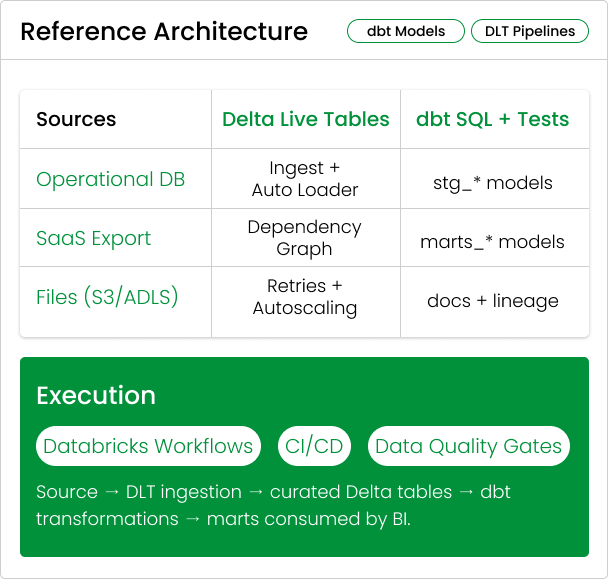
Automate dependency management and operational reliability without writing brittle orchestration glue.
Built-in dependency graph
Retries + autoscaling
Streaming or batch, same pattern
Write modular SQL, enforce quality with tests, and ship documentation with every change.
Jinja templating for reuse
Tests as a default, not an add-on
Docs + lineage generated from code
Same outcome, different clarity. Legacy ETL hides the rules inside a click-heavy tool. Modern pipelines keep the rules in readable files so teams can review changes and fix issues faster.

Issues point to a specific place, not a maze.

You can see exactly what changed and why.

Bad data is stopped before dashboards break.


We parse XML/JSON exports from legacy tools to extract SQL logic.

Refactoring monolithic logic into reusable 'Staging' and 'Mart' models.

Implementing GitHub Actions / Azure DevOps to test code before it hits production.

Setting up Databricks Workflows to schedule the jobs.
With DLT Expectations, bad data is quarantined automatically. No more broken dashboards.

Every run enforces expectations. If records violate rules, they’re dropped or isolated.

Changes ship with tests and docs. Review diffs like software.


From Informatica export to dbt models
DLT graph and operational guarantees
Tests + docs generated in CI
Promotion to prod with approvals
See a live demo of a dbt pipeline running on Databricks.
